What is Herd-MDL?
What is Herd-MDL?¶
Herd-MDL is a managed data lake in the cloud. The product helps manage data with the Herd metadata catalog, explore data with Herd-UI, and access data with the BDSQL Interactive Query tool. All this data is stored in cost-efficient, highly elastic cloud storage and is accessible from a wide variety of compute platforms.
What can I do with Herd-MDL?¶
Herd-MDL enables organizations to store, manage, process, and analyze massive amounts of data in the cloud. The initial use cases supported are:
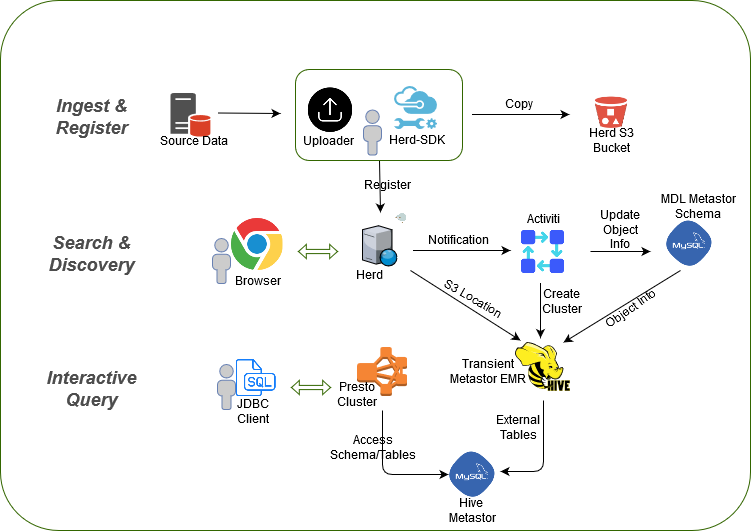
Search and Discover End users use Herd-UI to locate and understand data in your data lake. Full-text search of all descriptive metadata ensures that users can quickly find data of interest for their analytical needs.
Interactive Query SQL-based access to all data in the Herd catalog. A simple JDBC endpoint backed by a powerful Presto query cluster queries across petabytes of data and trillions of rows in seconds. And a native Hive Metastore interface is available for downstream access by tools in the Hadoop ecosystem, Spark, or other tools like AWS Athena
Ingest and Catalog Ingest data into Herd-MDL with proven high-volume loader utility or with API-based integration. Register data with the Herd catalog to enable search/discovery and interactive query capabilities.
Integrate Herd and Herd-MDL are API-first products. Teams at FINRA have integrated custom data intake apps, ETL frameworks, EMR-based batch analytcis, and data science tools including a native Spark library that reads directly from the Herd catalog.
How does Herd-MDL work?¶
This diagram illustrates how the technical components of Herd-MDL fulfull the use cases. For more information, see Technical Overview